There are a lot of different workflows in the world of modern development. Sometimes, it helps to prevent some problems during the development processes, but at other times, it may be more helpful to optimise the teamwork. In this article, we will analyse a few simple examples that demonstrate how a workflow may look, what its common practices are, when it is needed and how to change it.
As a start, let’s dive into an example of creating a new IT product.
Workflow
Suppose that you are on your way to creating a new IT product. The repository has been created, the code has been written and step by step, commit by commit, the master branch has been updated. Once the prototype is ready, tests are administered and passed to advance to the final building and deployment stages, and at the present moment, your application is serving the requests of your customers. What happens next? You receive your first feedback and requests from users to add new features, fix bugs and so on. To boost the process of deployment for the new versions of your products, you make the decision to invite a DevOps engineer to your team. The first thing that DevOps suggests is to build a CI/CD pipeline. The image below is a representation of how the CI/CD pipeline covers the workflow for the repository, which is the only master branch.

In this example, the pipeline is simplified to one environment. Everything looks good; the developer pushes the code into master, the pipeline is started, the code passes tests and the product is built and deployed in the environment.
Now imagine a situation in which a pipeline fails during the test stage.

The image above shows us that there are some critical errors in the existing version of the master, and it’s actually good that the pipeline failed; the broken app will not be deployed in the environment, and the errors will not affect service for your customers. The user is still happy! However, what will happen to the team of developers?
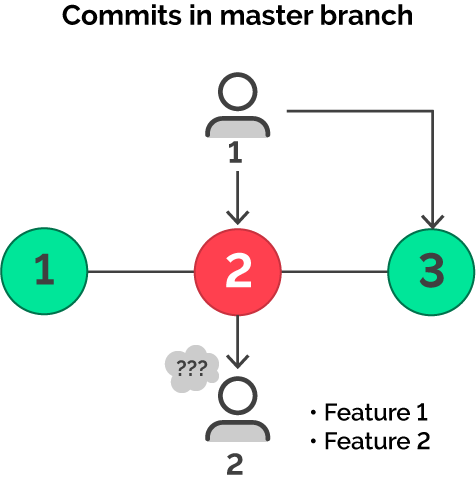
In the image above, we see that the first commit passed without any error and is currently deployed in the environment. The second commit is the point at which the pipeline failed. This is the most interesting part. There may be general agreement that the code in the second commit is broken and that it should be fixed, but what should the first developer start to do? What if we have a team in which every developer is working on his or her own tasks? The second developer may work on his or her own tasks to improve the product, but these features are based on the second commit, which is broken. What will happen with these changes? How much time should the second developer spend on this problem? Do the changes of the first developer affect the changes of the second developer? We have a lot of questions to answer, and as a result, we must deal with the following:
- Decrease in productivity
- Waste of time
- A lot of headaches.
To resolve these problems, we can change the workflow.
In the first step, let’s add well-known feature branches.
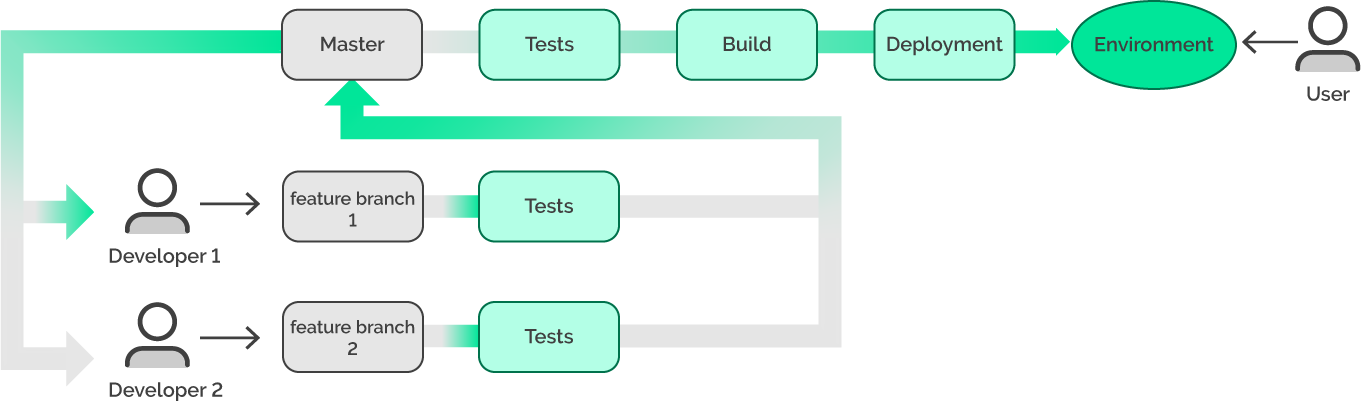
Now, every member of the team may continue their work without further stress provided that the pushing in the master branch will be blocked. From this point on, all new features will be added through the merge requests.
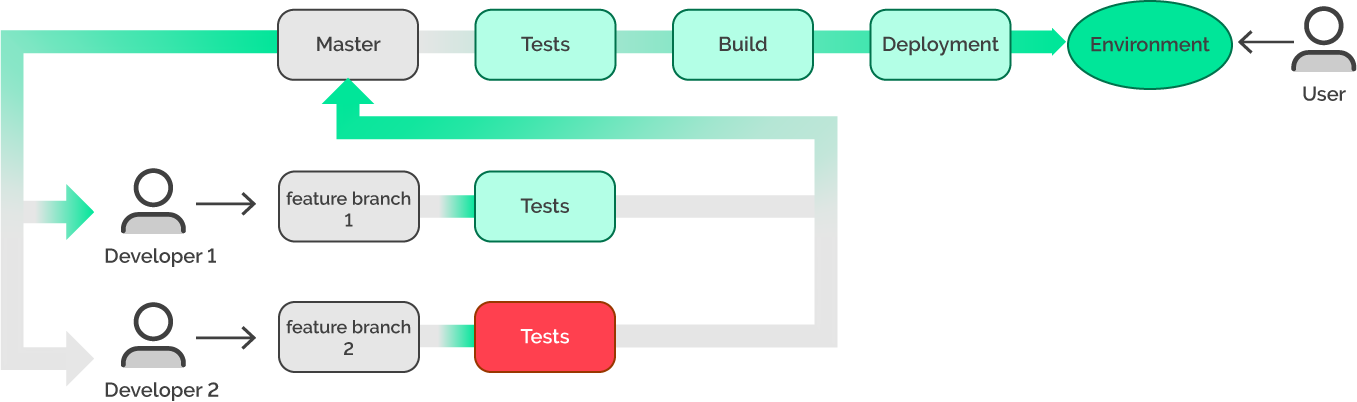
In the current workflow, if there is any problem with the feature, a developer may continue to work on it without affecting the other team members. In the meantime, the master branch contains only the code that works.
However, what if a new master is deployed, and a bug is found after the deployment?
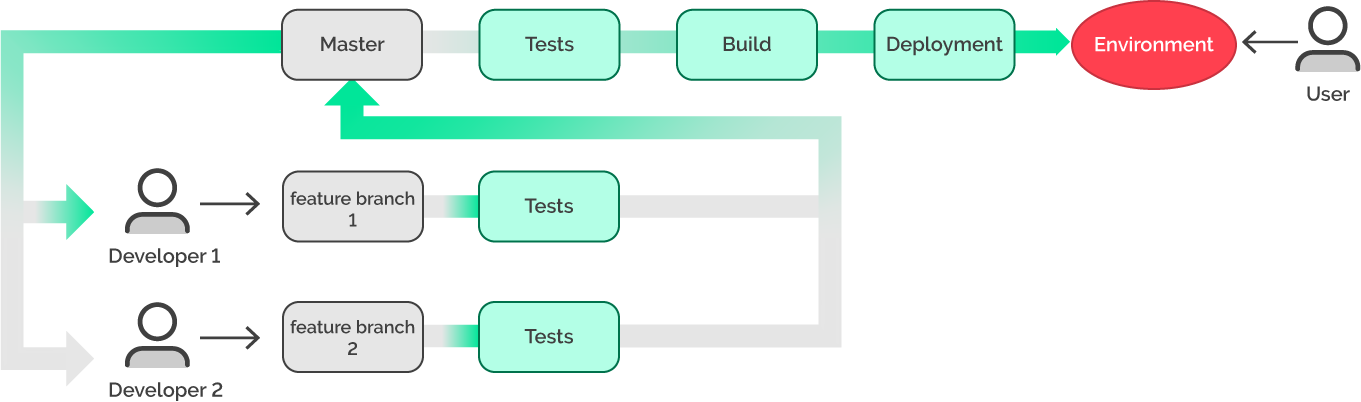
First of all, this would be a critical situation, since the client and stakeholders would all be displeased. It needs to be fixed as soon as possible. The logical decision in this situation is to roll back the commit in the master and re-deploy it. Which commit do we need? This time, when a bug is found, the master is updated with new features. Even if the necessary commit is found to be fast enough, there is still the question of what happened with the new feature that was based on a commit that contained a bug. Once again, we have a lot of questions.
It is important not to panic; let’s try to change the workflow again by adding tags.
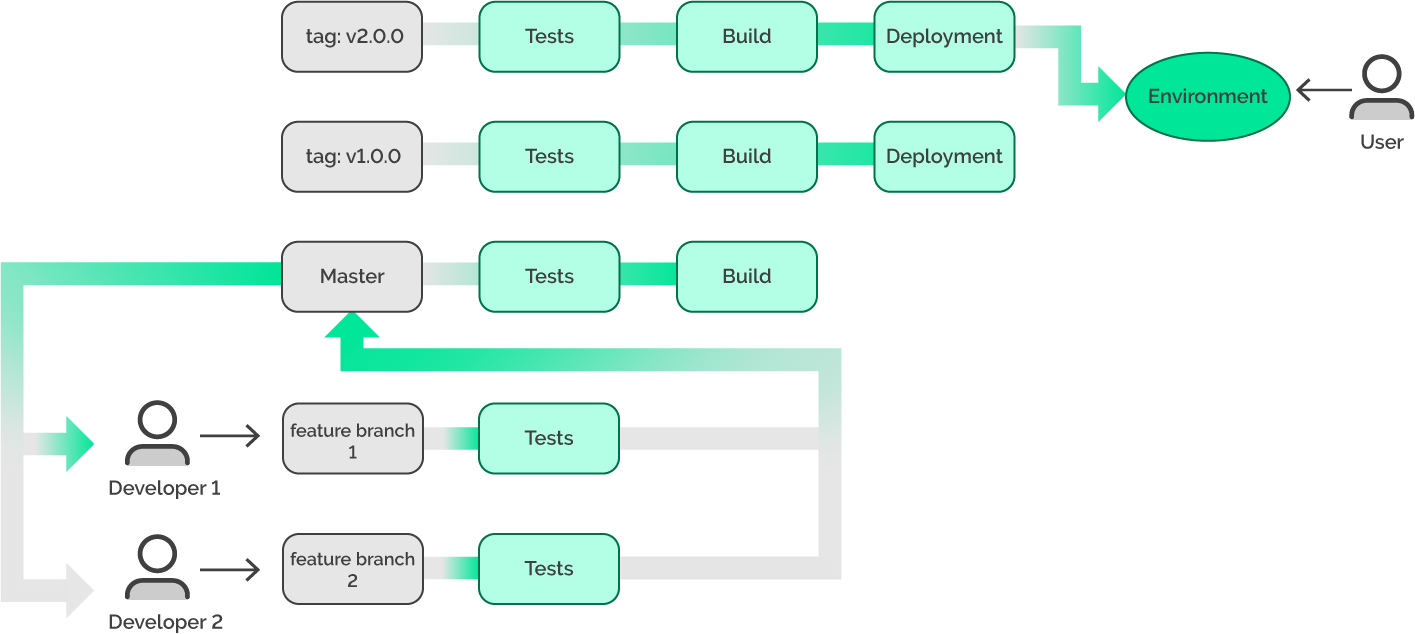
Tags allow us to fix a certain version of the application. Let’s re-play the situation in which the bug was found after the deployment in version 2.0.0.
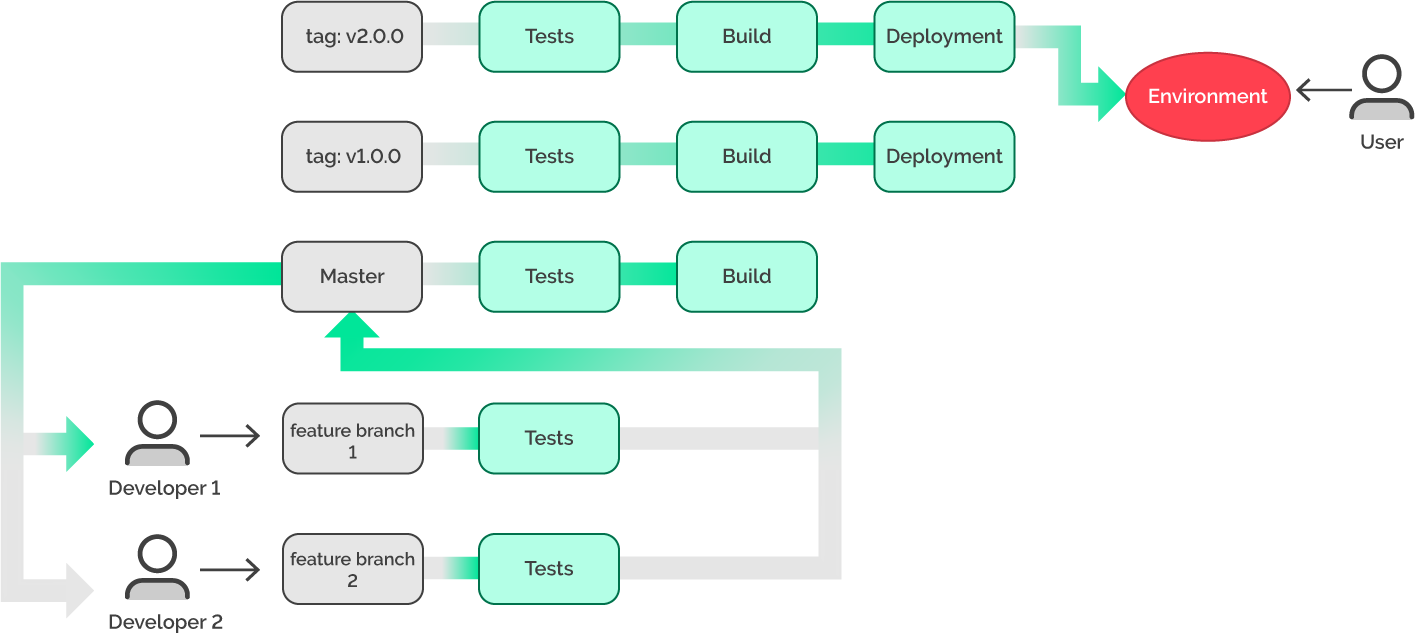
How can this problem be resolved now? Before version 2.0.0 was deployed, version 1.0.0 had been working well and without any problems (as we can see from the picture above). Now, in order to resolve our problem, we may re-deploy version 1.0.0, which had been working before.
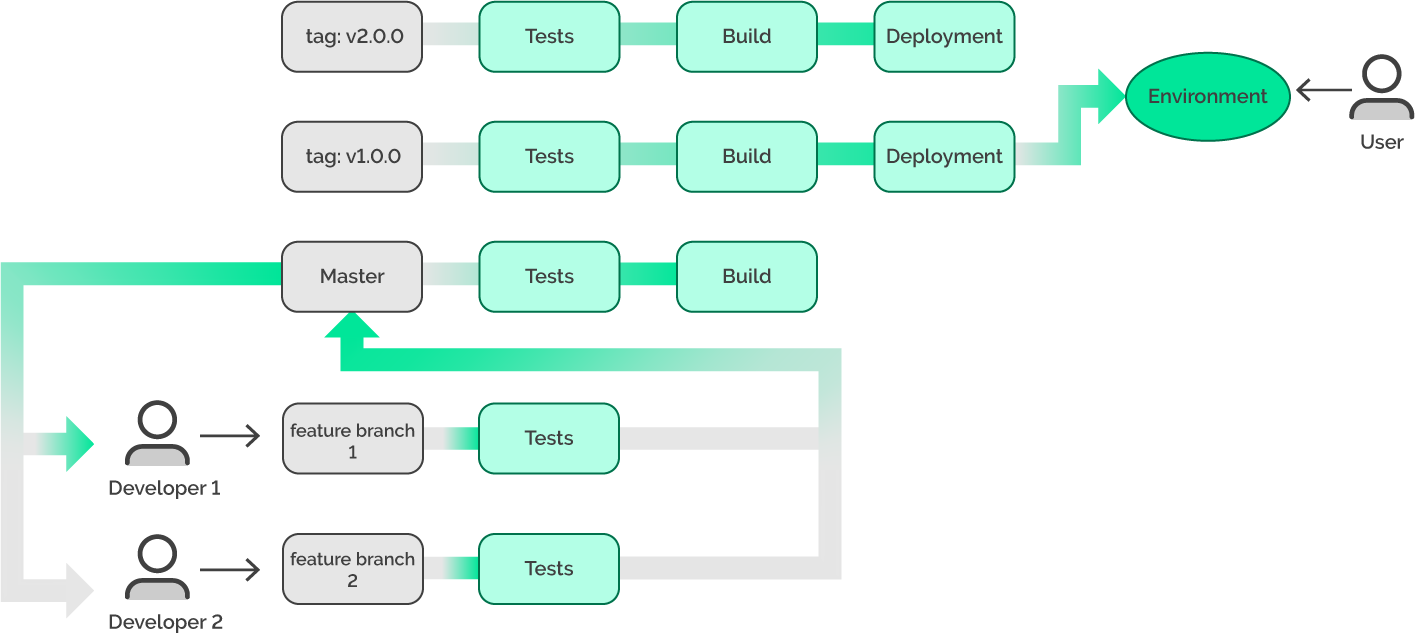
With the current workflow, our environment is fixed in the shortest amount of time, and without any actions from development, we achieved the following:
- Saving time and money
- Restoring the environment
- Preventing chaos
- Localising the problem in version 2.0.0.
This example shows us that changes in the workflow may help to avert a lot of problems with minimum spending. Still, what kind of workflow should we use?
As an example, let’s look at the well-known Git Flow:
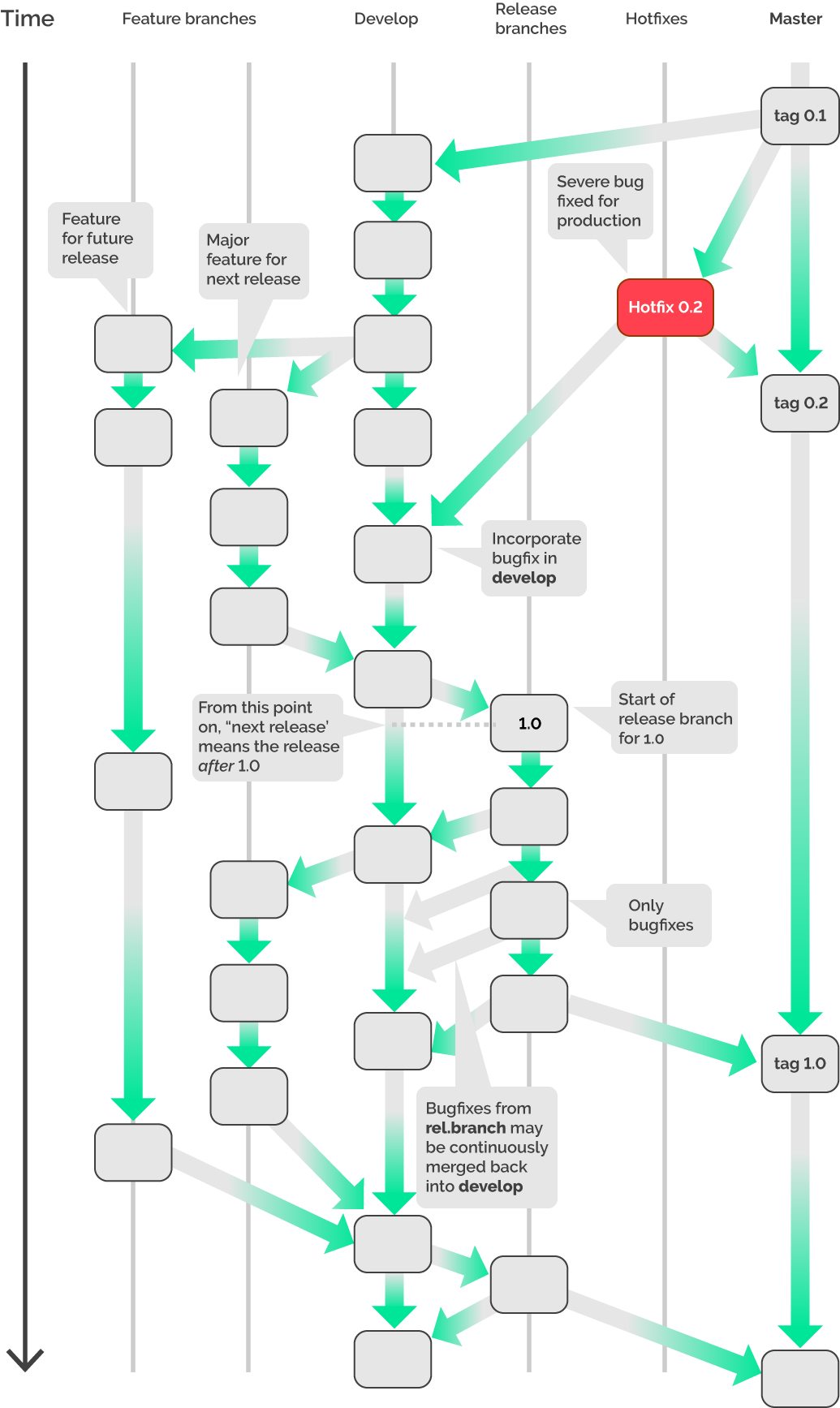
This model can be compared with our example. As opposed to our workflow, in this case, we have a develop branch and hotfix branches. This means that we definitely can’t say that we used Git Flow.
However, what if we were to add these branches from Git Flow to our example?
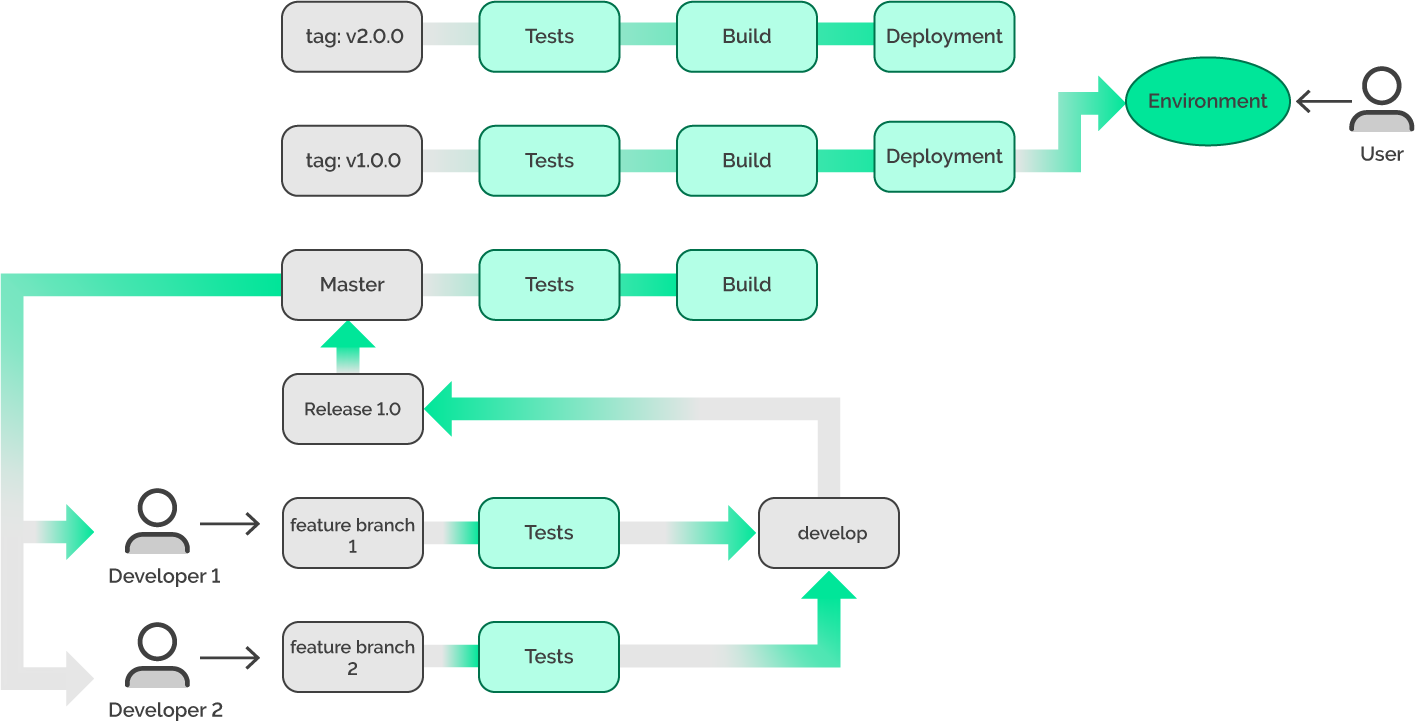
Now it looks like Git Flow, but what are the advantages? Which problems have been solved, and how does this improve our development processes? There is no answer to these questions. Yes, we obtained a canonical workflow, but at the same time, the process of development has become more complex. While this doesn’t mean that the Git Flow is not working, in this case, it may be excessive.
We can also compare our workflow with the GitHub Flow, another canonical workflow.
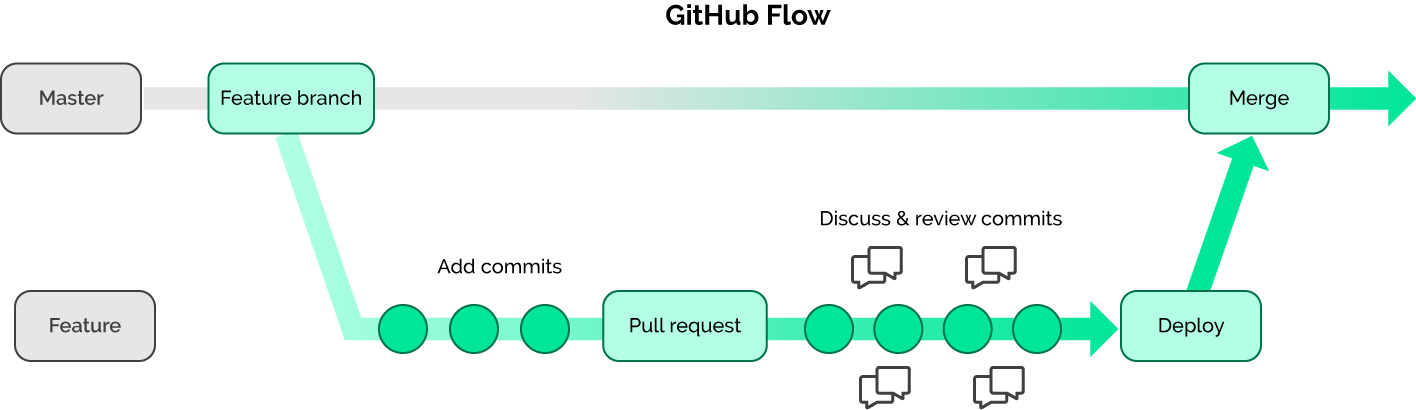
The first thing we may notice is that this model is simpler than Git Flow. In comparison with our example, there are no tags. However, we need this feature to resolve some of our problems. Once again, we can’t really say that we used one of these workflows.
It is important to understand that the existing patterns can help to build a workflow for a team that does not require that time be spent on the design. Sometimes, these patterns may fit perfectly, but other times, there may be an imbalance between the workflow and the real needs of a development team, and this could lead to undesirable results.
Don’t forget that the Git workflows are just tools, and as such, they should work to simplify our lives. Sometimes, we may just need to look at the problem from another angle.
The fate of DevOps
In the first part of this post, we looked at the workflow, so now let’s try to understand why the workflow is important for DevOps engineers. To do this, let’s go back to the process of building the CI/CD pipeline.
The process can be described in a simple picture:

Alternatively, it could be described with a simple question: how can the code from the repository be provided to the environment?
For this task, you need to understand which code should and shouldn’t be deployed. For example, if you are told that you must work according to the GitHub Flow, you must then search the necessary code for deployment in the master branch. Exactly the opposite would be the case if there is no workflow, which means that nobody knows where the necessary code for deployment is. In this case, you would need to build the workflow, and only after that would it be necessary to build a CI/CD pipeline. Otherwise, the wrong versions could be deployed in the environment, and as a result, users would lose their service.
The CI/CD pipeline may consist of many stages, and it can be prepared for deployment in different environments.
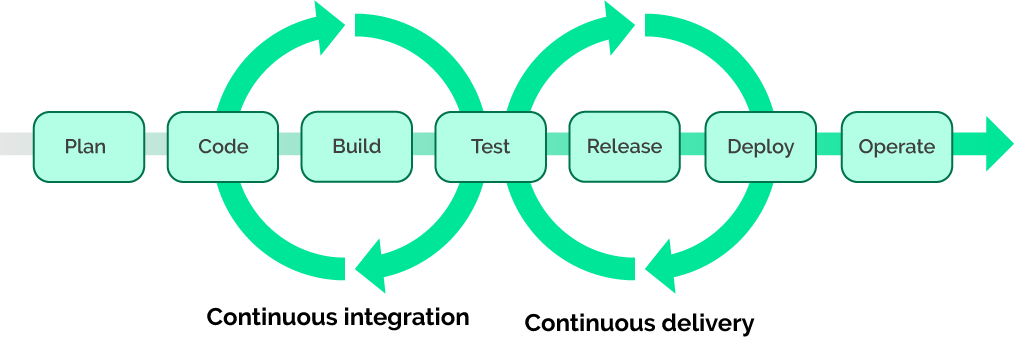
As an example, let’s look at the two main stages in CI/CD-pipelines: build and deploy.
The build stage is the process that leads from the initial source code to the final output artifact.
For simplicity, let’s add some conditions. First, the artifact should be versioned and kept in storage for future extracts. An important question at this stage is how these artifacts should be named. Again, let’s go back to our example when we used tags. In this case, we could use that tag for the name of the artifact and publish it in the environment. What if we don’t have a workflow? We could use a commit hash or probably the date to name the artifacts. Soon, though, it would be difficult to find the artifact that we need for the environment.
As an example, we can consider a real case. Here, we need to download the new version of Ubuntu OS. Instead of an elegant and convenient list of images, we see the following list of commits:
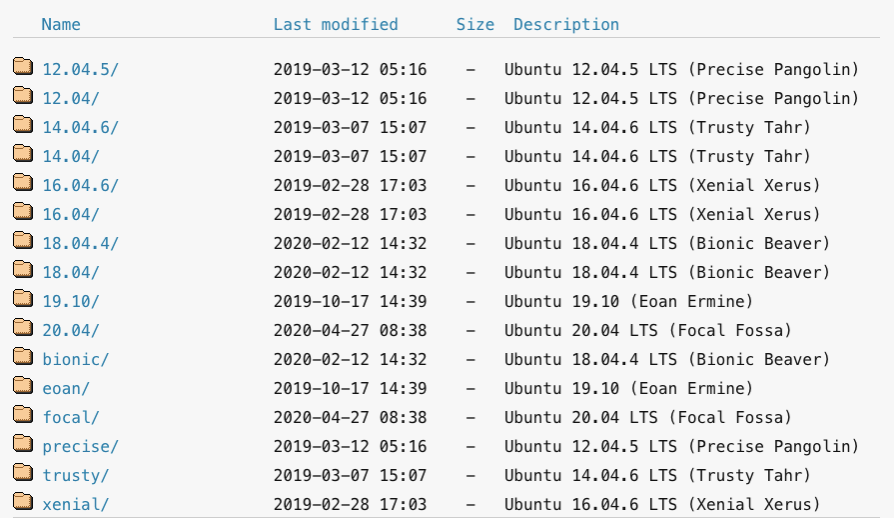
This will bring discomfort not only to the team but also to the user.
Of course, sometimes we can ignore the naming. Nevertheless, there is another case in which we may not have a workflow, and we may not know what to keep in our storage. In this case, we may be fraught with money issues since the space in storage may be limited due to overloading. Sure, we could publish artifacts from every feature branch, but this would one day lead to a situation where the resources would be depleted, and we would need to expand the storage by spending additional funds or using more human resources.
There are a lot of examples showing how a workflow is important in the context of building, but let’s go back to the issue of delivery/deployment.
Delivery is the process through which the artifact is manually extracted in the environment.
Deployment is the process through which the artifact is automatically extracted in the environment.
In the case of delivery, we may automate the process of extracting the artifact and start it manually. However, without a workflow, we will return the situation in which the bug was found in the commit, as shown in the previous examples.
In the case of deployment, we don’t have the right to use it without a workflow because it’s not possible to predict what exactly will be passed to the environment.
Therefore, we once again need the workflow, at least if the aim is to do everything well.
While we have considered only the build and deployment stages of the CI/CD pipeline, we can definitely say that the mess in the workflow will affect every stage of the CI/CD processes. Sometimes, the reason for this mess is not only the absence of a workflow but also its redundancy.
Conclusion
There are a lot of examples from the real world that demonstrate how certain practices work perfectly for some companies and teams, but this doesn’t mean that they will work in your case. Therefore, as you think about ‘why it doesn’t work’ or ‘what we need to make it work’, you should try to ask yourself, ‘Do we need it?’