This article may be useful for those who, like us, have suffered from the instability of external APIs. I will tell you what are the strategies for handling failures and which way we found to deal with a buggy email service.
Fault tolerance in brief
For starters, here is a brief and very simplified explanation of what fault tolerance actually is. The system is fault-tolerant if the failure of any of its components does not affect the overall performance. For example, the failure of the telemetry system should not affect the operation of the payment system. However, common practices such as horizontal scaling or backup instances may not be suitable if the component that fails is an external one, the fault tolerance of which one cannot guarantee for one reason or another. Examples of such problematic components are external databases or public API.
Building a cloud-based microservice architecture makes it easier to create a fault-tolerant system. Often, clouds support horizontal scaling and replication out of the box, guaranteeing the availability of cloud resources like message brokers; so, in general, they do their job well and are worth their price.
Our issue
 Chart 1: Architecture
Chart 1: Architecture
The purpose of our system is to monitor changes in stock prices and notify users in case of drastic price changes. To ensure the necessary level of fault tolerance, we chose a microservice architecture based on Azure Cloud, with Azure Service Fabric as an orchestration tool and Azure Service Bus as a message broker. Our system retrieves data from the exchange through Market Data Handler and then delivers it to the subscribers of the Price Change topic via Azure Service Bus. One of the subscribers is a service that is responsible for sending notifications and uses SMS notification and email mailing services.
The entire system worked just as planned until we noticed the mailing service shooting errors, and some notifications disappeared. The matter was also aggravated by the fact that execution of the same API method with slightly different parameters could be different: success (HTTP code 200) or failure (HTTP code 500 Internal Server Error). Unluckily, we were unable to convince our customer to use a more stable mail service.
Note: If you are not familiar with Azure Service Bus Queues and Topics/Subscriptions, please refer to this short article on MSDN first.
Strategies to handle failures
Fire-and-forget
Initially, we used the most primitive approach to resolving mail service failures, fire-and-forget, which basically means "just ignore the issue and it will be gone". In our case, this meant that, with any unsuccessful execution of the request, we should log an error and continue working further. However, since notification failure was a critical issue, this strategy had to be abandoned.
| Pros | Cons |
|---|---|
|
|
Circuit breaker pattern
To solve some issues related to the fire-and-forget approach, one may use the Circuit Breaker pattern (for more information, see MSDN). Its meaning is to minimize the number of requests until we are sure that the third-party service has been restored. This can be helpful in case of hitting requests limit as well.
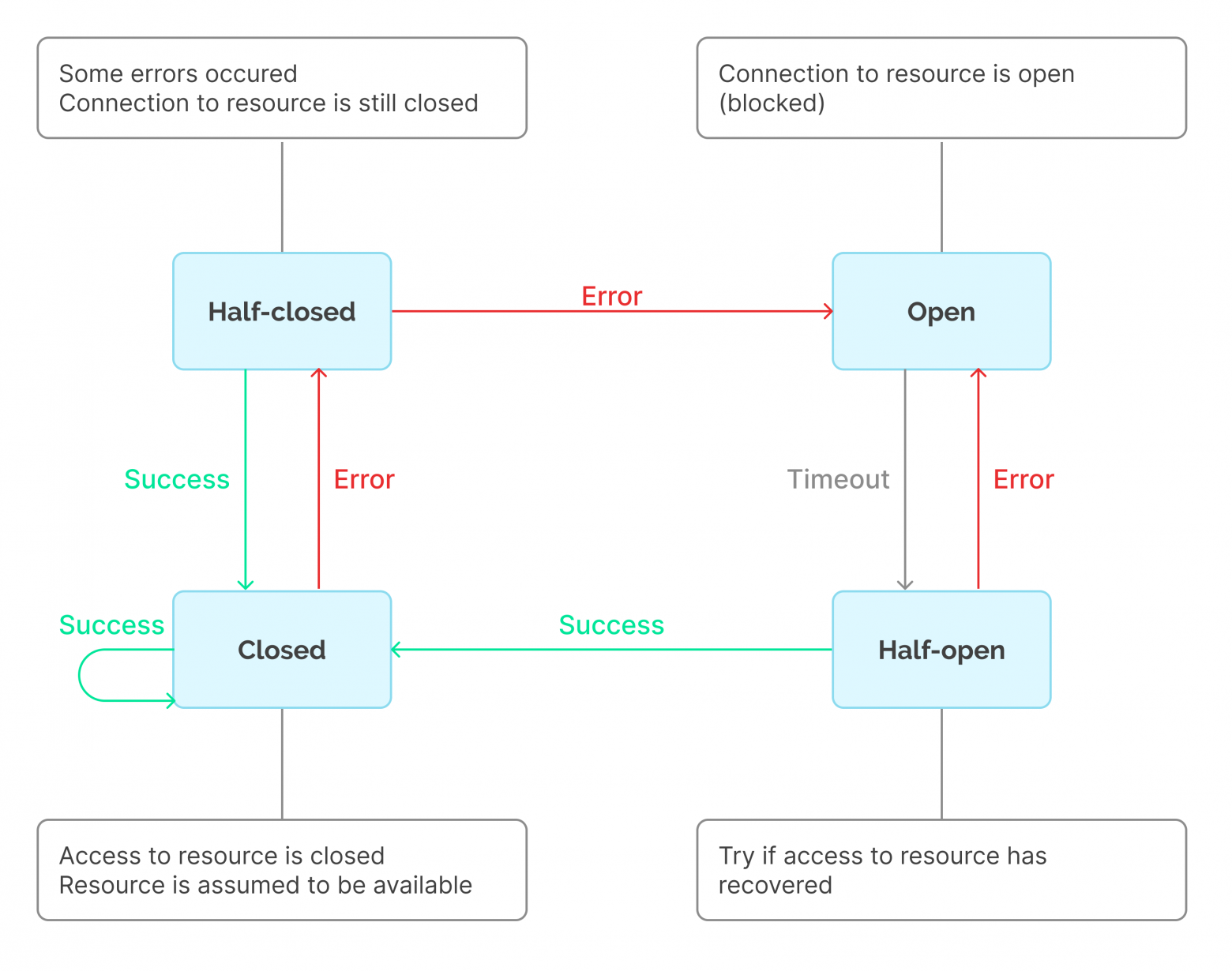 Chart 2: Circuit Breaker Pattern (Source)
Chart 2: Circuit Breaker Pattern (Source)
Usually, the Circuit Breaker pattern is implemented with the loss of unsuccessful requests, i.e. in conjunction with the fire-and-forget strategy. However, the approach can be modified: once a timeout occurs, the system reruns the last unsuccessfully executed message, while the rest goes to an external storage or a queue. With a smaller number of unsuccessful requests to the service, this approach allows you to guarantee the request processing. However, this may lead to inefficient resource consumption or overflow of the used storage or queue.
Using Circuit Breaker, we reduced the load on the mail service, but lost the ability to process notifications in parallel, which did not suit us either.
| Pros | Cons |
|---|---|
|
|
Schedule and retry
If fire-and-forget is not suitable and Circuit Breaker does not deliver the desired performance, the retry query strategy comes into play. The fact is that Circuit Breaker is best fit for handling scenarios, in which the service is unavailable. However, one may also encounter other issues, such as when the mail service was deployed with bugs, configuration errors, and subscription problems. Rerunning the requests routinely allowed us to automate the workflow while waiting for the solution that was on the mail service side.
Here is yet another real world example: the paid subscription for using the mail service ended and was replaced by a free plan, which limited the access. For a mail service, this may mean a smaller number of clients or some APIs, such as customer notifications by category, being unavailable.
Bottomline: not all errors are gone when you just rerun the requests. Typical 4xx errors for REST requests usually refer to an incorrect client configuration, and the result of such a request will most likely not change over time. Conversely, 5xx errors, e.g., 500 Internal Server Error, often occur due to service issues, so if the request is sent again once the service is up and running, it will be a success.
In our case, everything was much simpler. For some unknown reason, the mail service accepted one type of request for one group of people, but not for another. Other requests ran successfully for the latter group but failed for the third one. At the same time, all unsuccessful requests were repeated with the same result until the mail service got repaired. In other words, we could not identify and fix the error, but we were just able to wait until the error was gone.
 Chart 3: Partial failure of external service
Chart 3: Partial failure of external service
Rerunning requests using message queues
 Chart 4: Architecture with a message queue
Chart 4: Architecture with a message queue
This strategy implies retrying unsuccessfully executed messages that were previously stored in the message queue. For each unsuccessful execution, the message is scheduled for re-processing with a delay.
There are some algorithms for calculating the delay before the next processing:
- constant backoff: a constant value, e.g., 5s
- jitter backoff: a random variable in a constant interval, e.g., between 1s and 10s, with a normal distribution
- linear backoff: a linearly growing value
- exponential backoff: An exponentially growing value
- exponential with jittered backoff: an exponentially growing value with a random deviation.
") Chart 5: Various approaches to delay algorithm calculation (each lower algorithm means a better one)
Chart 5: Various approaches to delay algorithm calculation (each lower algorithm means a better one)
For our system, we picked the exponential with jittered backoff approach, as it minimizes the load on the external service and distributes the peak load. We opted to retry messages only for 24 hours, since the notifications become irrelevant after this time lapses. In order to stop retries and enable manual processing of notifications with an exhausted number of retries, one should use a dedicated queue, e.g., a Dead-Letter-Queue available for each Azure Service Bus Queue by default. This way, every message that exceeds the maximum limit of retries falls into Dead-Letter-Queue.
There are some specific issues Azure Service Bus Queues have:
- If Azure Service Bus is configured to detect duplicate messages, each message scheduled for reprocessing must have a unique identifier, which complicates the collection of metrics.
- You may fully provision message rescheduling at an “atomic” level only with a single Message Queue.
| Pros | Cons |
|---|---|
|
|
An attentive reader may notice that we could have used the existing topic, and the final chart would then look like this:
 Chart 6: Retrying with an existing Service Bus Topic
Chart 6: Retrying with an existing Service Bus Topic
This solution is actually problematic, as any unsuccessfully processed message is sent back to the topic. If there are other subscribers to the topic in addition to our service, they will receive duplicates of unsuccessfully processed messages, which is undesirable in general.
Combining rescheduling and circuit breaker
 Chart 7: Hybrid approach combining Rescheduling and Circuit Breaker
Chart 7: Hybrid approach combining Rescheduling and Circuit Breaker
To optimize the number of unsuccessful requests, one may also use the Circuit Breaker approach. Logically, if one of the requests was executed unsuccessfully, then the subsequent one will end with the same result. Using this heuristic, all subsequent unsuccessful requests will for some time be immediately sent to the retry queue. In this case, we sacrifice the speed of notification delivery, but at the same time reduce the load on the mail service, thus eliminating the possible root cause of the failure. However, this strategy was out of the question, as our customers' money is much more important. The main risk of this approach is that some messages may never be processed at all.
You may now ask why we did not use multiple Circuit Breakers for different patterns of using the mail service, which could speed up message processing. This was not possible, as the provided API contained many unrelated parameters. Each combination of those parameters would require a separate chain, repeatedly complicating the development, support, and diagnostics of the service.
Common issues with retries
Idempotence
Idempotence is a property that guarantees the repeated calls to the same operation will not cause any changes to the state of the service or lead to any additional side effects.
Here is a typical example:
- A synchronous request to send a notification to the mail service started.
- The mail service accepted the request and successfully sent the notification to the clients.
- At the time of sending a response on successful operation, the connection failed, which returned the initial request to send a notification unsuccessful.
- Additional requests to send this notification did not result in clients receiving duplicate messages.
 Chart 8: Example of idempotent key extraction by core properties: quote, price, and timestamp
Chart 8: Example of idempotent key extraction by core properties: quote, price, and timestamp
The idempotence of services is usually provided by an additional request parameter, the idempotence key. An example of such an API is Stripe. To determine the idempotence key for both the original message and the re-processed one, one may use the hash of the message content or that of the unique fields.
Message order and timeliness
Rescheduling the messages for subsequent processing leads to their reordering. Thus, we can first successfully process the most important request and then the less time-sensitive one. For a mail service, it could work like this:
- Message A was received at 10:00.
- Message A could be delivered, with the next sending being scheduled for 11:00.
- Message B was received at 10:30 and contains the most up-to-date information on the subject of message A.
- Message B has been sent successfully.
- At 11:00 message A is sent successfully with outdated information.
 Chart 9: Example of using a Key-Value storage in order to ignore stale message processing
Chart 9: Example of using a Key-Value storage in order to ignore stale message processing
One of the solutions to issues of this kind is based on the use of caches. Each message is assigned a key identifying the topic. This key is used to store the time of the last successfully sent message on the appropriate topic. Messages from the processing queue are sent only if there is no record in the cache with a more up-to-date message.
Limits on retries
Needless to say, it makes no sense to endlessly retry sending messages, since this will lead either to the queue overflow at some point in time or to a large unnecessary waste of resources. After exceeding a reasonable limit for re-processing, e.g., 10, the message gets into the Dead-Letter-Queue, which is a special queue that could be checked in automated or manual mode. Also, when using delays before re-processing, one may usually determine heuristically when the message will become irrelevant. For example, notifying a client about a significant change in the stock price that occurred two days ago may only trigger negative experience.
Re-prioritizing messages using priority message queues
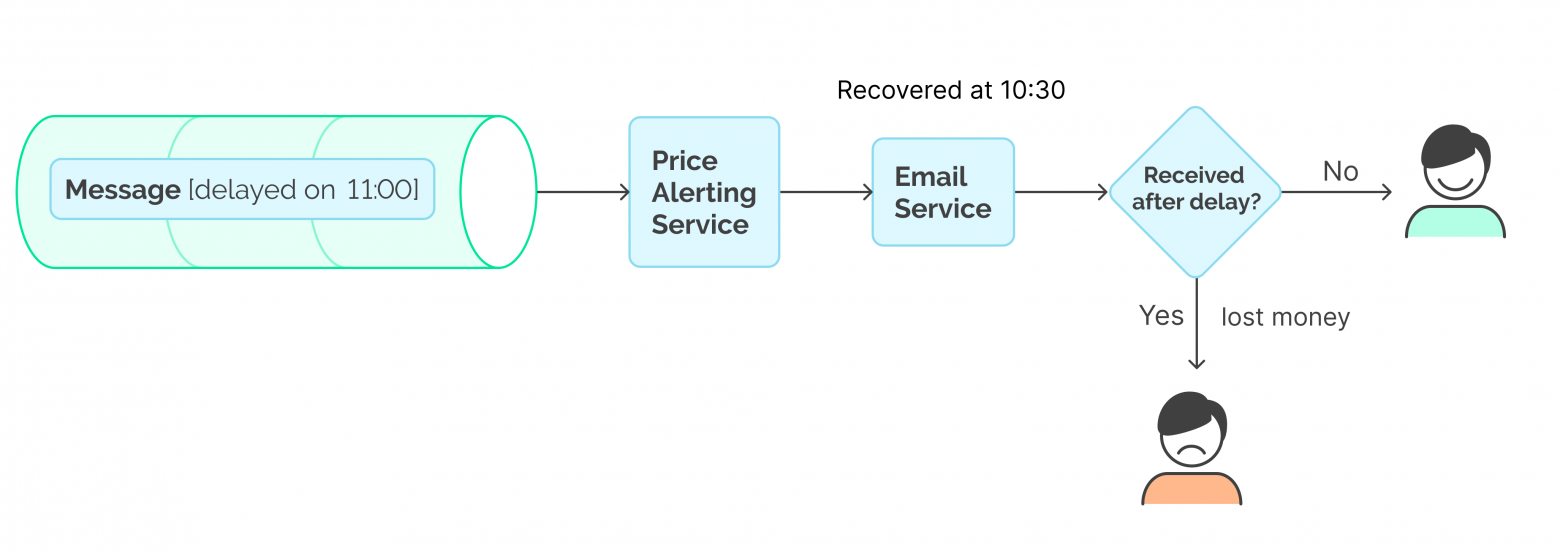 Chart 10: Rescheduling strategy issue
Chart 10: Rescheduling strategy issue
Despite the previous approach did meet our needs, I would still like to mention a slightly more advanced one. This is because the retry delays negatively affect the final processing time of the message, while our customers would be more than happy to receive a notification immediately once the mail service is up, and not with an additional 30 minutes’ delay.
 Chart 11: Example of a single message queue without delays between retries
Chart 11: Example of a single message queue without delays between retries
Let's assume that instead of calculating the time for subsequent processing, we would simply put the message at the end of the queue. In this case, the message re-processing would most likely have been performed too early, before the original issue had been solved. This would lead to a small collapse, slowing down the execution of higher-priority and/or newer messages.
 Chart 12: Example of using a priority message queue
Chart 12: Example of using a priority message queue
Using priority queues for message re-processing enables giving priority to the most relevant messages, i.e., with fewer processing times. Thus, all new messages are processed first, then the ones that have already been processed once, then those processed twice, and so on.
 Chart 13: Rescheduling with a priority message queue
Chart 13: Rescheduling with a priority message queue
 Chart 14: Message flow with a priority message queue
Chart 14: Message flow with a priority message queue
| Pros | Cons |
|---|---|
|
|
Applicability in monolith architectures
While fire-and-forget and Circuit Breaker are regular guests in monolithic architectures, message queues are less popular. This is because such architectures are generally aimed at reducing the number of external resources used and delays due to data transmission over the network. Based on this, it is usually recommended to use message queues in the application memory rather than any external ones. This, of course, reduces fault tolerance; however, it is the most productive approach that does not require any additional infrastructure costs.
Message queue limitations
Let's take a look at the most popular message queues, such as Apache Kafka, Rabbit MQ, AWS SQS, and Azure Message Queue.
| Technology | Supports Message Scheduling | Supports Priorities |
|---|---|---|
| Azure Message Queue | Yes | No |
| Rabbit MQ | Yes | Yes |
| AWS SQS | Yes | No |
| Apache Kafka | No | No |
You may now be asking: what can one do if chosen particular message queue technology does not support priorities? For example, the popular Kafka supports neither priorities nor delays. In this case, we could use multiple queues for messages with different priorities or delays. For example, a priority queue can be emulated by creating queues for each priority level: ‘message-queue-retry-1’, ‘message-queue-retry-2’, etc. To emulate delays, it is possible to create queues for each fixed delay value: ‘message-queue-1min’, ‘message-queue-5min’, etc. By adding metadata on the minimum processing start time to the message, you can sequentially extract messages from the queue, blocking the execution flow and thus preserving the message sequence.
 Chart 15: Priority message queue emulation with simple message queues
Chart 15: Priority message queue emulation with simple message queues
In addition, it may be handy to learn about the bucket priority pattern: here.
Apart from message queues, one may also use task schedulers, which commonly leverage database tables to store messages. Quartz and Hangfire are good examples here, although they are usually not scalable and less efficient.
Conclusion
There are many ways to handle service failures. The most common method is fire-and-forget, the simplicity of which is impressive. The next level of processing that reduces the number of unsuccessful requests is the Circuit Breaker pattern. If you need to achieve successful processing of each request, you can use queues to store messages scheduled for reprocessing. To regulate the compromise between the number and frequency of requests to the service, you should choose the appropriate function for the delay before reprocessing. For most use cases, a constant or exponentially increasing jittered delay will be suitable. To minimize the message processing time, you can use priority-enabled message queues, thus decreasing the delay before re-processing.
In our case, the use of the message processing rescheduling approach with a message queue allowed us to guarantee the delivery of notifications and at the same time minimize the cost of the system.