One of the long-term projects we are working on is a Learning Management System (LMS) that helps to organise, track and distribute online courses. The LMS provides a rich variety of online tools that are vital for all aspects of the educational process, including general user management, course management and planning tools, attendance tracking, assessments, and academic reports. The system we are working on is one of the leading platforms across Europe and the USA. The platform is available 24/7, and the number of active users exceeds seven million per day.
This article illustrates how the release process of the high-load platform was transformed from occasional and costly releases to more frequent and predictable ones.
Before transformation: Release highlights
Several years ago, the project began rapidly gaining market share. Not only did this result in team growth, but it also revealed a scaling issue. Even though the LMS users were eager to pay for the service and custom development, market expansion was slowed down by infrequent releases because some organisations could not wait that long for new features.
At that time, there were 3–4 releases a year, each of which was preceded by a full regression testing, which lasted 2–3 weeks and stopped new development completely. Developers and testers had to manually pass hundreds of complex and detailed test cases to ensure the quality of the product. Apart from resource costs, the regression was quite tedious for everyone involved.
Unfortunately, there was no immediate way to start more frequent releases due to the monolithic architecture and the requirements imposed on the platform.
Monolithic architecture
Initially a student project, the system was originally developed in C++ and then flowed into a long phase of development in ASP.NET. Many patterns and best practices that are well-known today were in their infancy at that time, and .NET 2.0 did not have even half of the features that exist in modern .NET Core. What some may call a smelly code today was not considered to be bad back then. Therefore, the monolithic system architecture (composed as one piece) actually suited everyone until a certain point.
In terms of releases, the architecture was inflexible because releasing components simultaneously was the only possible option. Such releases were followed by increased time costs and higher risks of having deployment issues in production. Addressing the risks became the main reason for having mandatory regression testing before the release roll-out.
Strict requirements
The LMS is the core of education in many European universities and colleges. All data related to students, teachers, parents, user interactions, grades, presence, learning resources and homework, among other features, are stored by the platform without hard copies. The system has always been subject to extremely strict security, performance and, importantly, availability requirements. Now imagine that the system that acts as your central working resource and wholly covers your daily workflow is suddenly broken. Five minutes of unavailability will cause you slight discomfort, while one hour of downtime will completely block you from performing any work-related tasks. That said, uptime—a period when the system performs normally—is one of the key metrics and is also a legal obligation. Failure to comply with uptime regulations can bring big fines. The target uptime for this LMS is normally 99.9% or above.
Simultaneously, release is a threat to production stability because of potential code and deployment issues. The system aggregates dozens of components, including web applications, async services and APIs. Considering the complexity, potential deployment issues are very real and can cause significant downtime.
Thus, the paradox of the situation is that from the user point of view, more frequent releases are crucial; meanwhile, IT operations engineers who are responsible for production stability and maintenance (hereafter ‘Operations’) would prefer as few releases as possible.
Underperforming routines
One of the most important reasons for rare releases was the release management process. There is a separate chapter in this article describing then-existing process, its weak points and transformation.
Transformation
With an awareness of global issues and a clearer understanding of what we would like to have in the end, the company began to gradually change.
In this article, I will focus on the changes in the development and release process, but it is worth noting that a lot of changes have occurred in the work of Operations as well.
Infrastructure issues resolution
In the beginning, we had to overcome some infrastructure issues.
First, it was difficult for many teams to work on isolated features because we were using TFS as a source control. It turned out that Git meets all our criteria, and it is much easier to maintain the new branching model based on Git. Thus, we moved from TFS to Git and changed the branching workflow along the way.
Second, the deployment procedure consisted of an indefinite set of PowerShell scripts that had been written by different people for different purposes, and they were sometimes difficult for the majority to understand. Even though they served their purpose, maintaining them required increasing effort as the number of new components started to grow. To resolve this issue, we developed an internal deployment tool that automates the execution of deployment steps and organises them in execution sequences. It also creates deployment logs.
As a part of the development of a new component, developers and Operations discuss the requirements for the new application and how it will be deployed. Developers are responsible for creating a script that automates the deployment of the tool. The script is an environment-independent parametrised sequence of steps, whereas script variables such as paths, URLs, and server names are configured for a certain environment. Using the same deployment tool in both test environments and production allows deployment issues to be found and fixed at an early stage.
Although the solutions to both problems have been described here briefly, they require much effort, coordination and time.
Timeline shortening
We adopted the concept of ‘release trains’ that ‘depart’ according to the schedule published in advance. The dates of several upcoming releases are now announced beforehand. In the event that some teams cannot make it on time for a certain release, they will have to miss it and should therefore aim for the following release. This rule allows for the planning of feature delivery and is more accurate in customer commitments.
We started with a few timid attempts at monthly releases of the main application and then gradually moved on to releases every second week. Short release cycles had a beneficial effect on the quality. Less code means fewer risks and a higher probability of catching all bugs before the release.
Nevertheless, after a couple of years of biweekly releases, we decided to jump back to monthly releases due to the amount of manual work needed for the release preparation. In addition, frequent releases were exhausting for a handful of QAs because they had to consistently split their time between their regular teamwork and the release tasks. Monthly releases became a compromise between fast feature delivery, a smaller scope of changes and employee comfort.
Timeline example
Let us examine a standard release iteration using the reverse planning method and see why it takes five weeks for a release. Given that the release date is scheduled and the stabilisation testing together with staging takes two weeks, we arrange the code freeze two weeks before the planned release date. A code freeze implies that it is no longer possible to merge new features with the release. All new features aiming for the release must be merged by the code freeze. Features that were not merged before the code freeze except some important ones negotiated in advance are re-targeted to the next release.
Also, we know that translation testing is one of the acceptance criteria, and this step is dependent on the translation agency. It takes around a week to receive the translations from them and another week to verify the translations. Therefore, two weeks before the code freeze, we have the language freeze, which is the day when we send new strings for translations. After the translations have been received from the translation agency, teams finalise the testing and merge the feature.
Regarding post-release activities, we monitor production logs for one week starting from the release day. Within this week, it is important to ensure that the release did not introduce new issues. If it did, we must decide whether to fix them before the next scheduled release.
See an example timeline below:
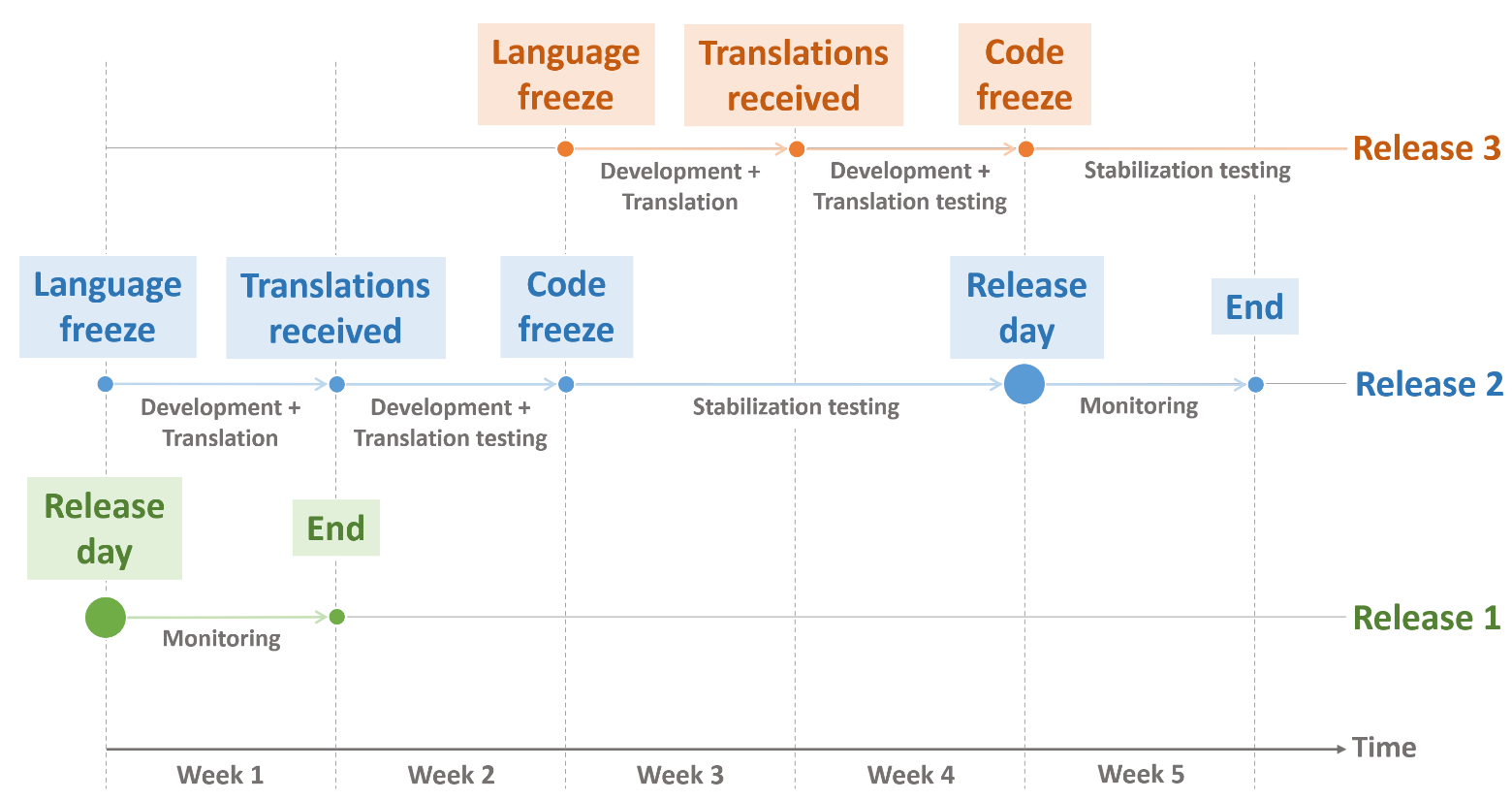
When releases happen every second week, three release iterations can overlap at a certain time. Monitoring of the previous release, stabilisation testing of the upcoming release and translation of the next release can be run in parallel.
With monthly releases, we reserve two-week windows without release work between release stabilisation tests.
New branching strategy
Previously, we did not really care about the branching strategy because the development was put on halt when the regression testing started.
The branching scheme we came up with was not invented by us, but it completely meets our needs:

We have two long-living branches: develop and master. The code in the master branch must match the version in production at any given time. Branches for patches and hotfixes are created from the master branch and merged to it immediately after release. Accepted features without bugs are merged to the develop branch. When the stabilisation testing of the new release starts, a release branch is created from the develop one, after which they live apart. New bugs found in the release are fixed in the release branch and continuously merged to the develop branch. New features are collected for the next release in the develop branch again. When the stabilisation is finished and the release package hits production, the release branch is merged to the master branch.
Release candidate testing changes
As the new paradigm left no time for long testing, we decided to abandon the full regression testing in favour of critical area testing. We composed a list of core features that must be checked before a release. These features only include the most used functionalities. We continuously reduce the amount of manual testing by covering the critical areas with Selenium tests.
Previously, we could find dozens of bugs during the regression testing and then spend time fixing or rolling them back. Sometimes, this would result in postponing the release day. According to the new definition of ‘done’, only functionalities that have been verified by a QA and PO can be merged to the develop branch. With this in mind, we only kept a brief testing stage for the new functionalities on the release candidate to cut off integration issues.
Abandoning the pre-release regression was not easy. It scared us in the beginning, but fortunately there was no noticeable degradation of quality after all.
Architecture changes
Releasing a monolithic system was difficult, risky and time consuming. Moving on to frequent releases forced us to break the system into single deployables, which are smaller components that can be stored and released separately from each other. Although we have already extracted many components, there are still candidates that can be moved to a separate repository on the list. For greenfield development, new components must always be built as single deployables.
Release management transformation
In such a big project, it is vital to have a person who coordinates all participants and is always on top of everything during the release. This person always knows the current status and communicates with stakeholders and teams about found issues or timeline deviations.
The release manager role has existed since the beginning, but historically, it was a more senior title that could only be awarded to 2–3 chosen senior developers. On the one hand, it guaranteed some stability. On the other hand, it had obvious drawbacks.
First, given the level of responsibility and the length of the release cycles, this was a very exhausting job, so no one wanted to have it on a regular basis. The job needed to be delegated to a wider range of capable people.
Second, every new release was somewhat different from the previous one because release management was a sort of creative task rather than a well-defined routine.
The initial goal was to clarify the duties and scope of responsibilities of the release manager. This was not a low hanging fruit, but not only did we figure them out, but we also documented them in a very detailed way, which guarantees that every experienced developer can take on the release manager duties without a fear of failure by missing important details. We also documented the components and the dependencies between them, the deployment sequence, the release timeline and other related areas. The more detailed the description of the complex process, the easier it is to find a solution to any issues that may arise. When release management tasks that must be solved individually become part of a regular routine, the release manager can focus on more important things. One could say that we introduced unnecessary bureaucracy, but in this case, it proves to be justified.
The solution above serves many purposes. Among the obvious advantages are that the release manager is now a non-person-specific role, we now have a bigger pool of release managers in the rotation plan, the pressure on key people has eased, and an accurate idea of the amount of release manager work has emerged.
Below is an incomplete list of release manager responsibilities:
- Taking care of translations for the new functionality;
- Defining the timeline of the release;
- Figuring out the scope of changes and potential dependencies and estimating the risks;
- Creating the release branch and deploying it to the test environment;
- Maintaining the test environment during stabilisation testing;
- Monitoring logs on test environments, investigating new issues, and assigning found bugs;
- Keeping in touch with the QA coordinator (a person who manages the stabilisation testing) and helping to resolve all their issues regarding the ongoing release;
- Communicating with the release team, PO, Operations, etc.;
- Reviewing all merge requests sent to the release branch;
- Handing over the release candidate package to Operations for staging;
- Monitoring logs in production for one week starting from the release day;
- Coordinating hotfixes and patches if needed;
- Participating in a release retrospective.
What is NOT included in the release manager’s responsibilities?
- Deploying the release package to production (Operations’ responsibility)
- Fixing found issues (development teams’ responsibility).
Does it sound too ideal?
As with our many other projects, we have sought a balance between developing new features and technical improvements that do not add value for end users. Therefore, automation of the regression testing is not 100% complete yet.
In reality, sometimes new issues are squeezed into the release candidate, and we need to follow up on them quickly. Also, releases can be cancelled or postponed for various reasons, such as critical last-minute findings, ongoing Operations routines (e.g., data migration or the installation of new hardware or software updates), and even long holidays. Lastly, bad releases that require urgent patches can arise as well.
During the COVID-19 lockdown period, the load on the platform increased dramatically. The growth of the number of concurrent sessions and user actions revealed some bottlenecks that had been hidden, so all planned releases were postponed, and patches and hotfixes became the highest priority. When this high-pressure period was over, it turned out that we had an unexpectedly huge number of new features awaiting the release; stabilisation testing took a long time, and the number of new bugs in the package had doubled. However, the release was still less risky and less costly than before the transformation.
Perspectives
The progress is irreversible. After every new release, we set aside some time for introspection to define the pain points and work on our mistakes.
However, the destination we are moving towards is crystal clear. We aim to:
- Extend the automation testing so it covers all critical areas;
- Have release cycles that meet our needs. They may get shorter again, but most importantly, they should be as smooth and imperceptible as possible for both the users and engineers;
- Extract as many components as we can that can be released separately.
Conclusion
Releasing a new version of a complex web application is a challenging task. In several years, we have managed to step away from quarterly releases towards biweekly ones, but we eventually settled on monthly releases. This transformation required comprehensive changes affecting Engineering, Operations and Management. In the end, the scope of the releases decreased considerably, and they became less risky and more predictable from the planning point of view. The era of tedious, resource-consuming releases is now over.